

ColumnStore index en SQL Server
La importancia de los índices en las consultas radica en que estos van a permitir optimizar la obtención del conjunto de resultados.
Los índices son estructuras que ordenan los registros de una tabla o vista por uno o más campos de manera ascendente o descendente.
Los índices en una tabla o vista guardan todas las columnas del registro, si es necesario buscar un campo de un registro específico lo que hace la consulta es leer toda la fila y luego extraer el dato que se requiere. Los Column Store Index almacenan los datos en columnas, esto mejora la compresión de datos, reduce considerablemente los datos de E/S ya que se leerán solamente las columnas necesarias y mejora el desempeño. En este artículo se va a explicar el uso de los Column Store index.
Para mayor información ver
Indices en SQL Server
Indices en vistas en SQL Server
FileStream en SQL Server
Agrupamientos en SQL Server
Beneficios de los ColumnStore index
- Proporciona un nivel de compresión mas alto, aproximadamente 10 veces.
- Mejor rendimiento de los índices B-Tree.
- Se pueden hacer filtros en índices desde SQL Server 2016.
- Óptimo formato de almacenamiento para Datawarehouse y Analytics.
- Usan menos memoria debido a la alta tasa de compresión
- Reduce el IO total al leer solamente las columnas necesarias en la consulta.
- A partir de SQL Server 2014 se incorpora un Clusteres columnstore index que es actualizable.
- Es posible usarlos en ambientes AlwaysOn.
- Mejora el rendimiento en agrupamientos
- A partir de SQL Server 2016 se puede modificar los datos de la tabla que tiene el índice ColumnStore sin tener que eliminar el índice y luego de los cambios volver a crearlo.
Consideraciones
- No se permiten tipos de datos ntex, text, image, varchar(max), nvarchar(max), jerárquicos ni espaciales.
- En SQL Server 2014 sólo estaba disponible para la versión Enterprise.
- No se permiten tablas con fileStream
- Necesita un espacio adicional para almacenar las columnas elegidas.
Ejercicios
Usando la base de datos Northwind
use northwind
go
Ejercicio 1
Crear una tabla Prueba e insertar registros, en este ejercicio se explica como crear un índice ColumnStore no agrupado.
Drop table if exists dbo.Prueba
go
Create table Prueba
(
Codigo int,
Fecha Date,
Dato1 nvarchar(30),
Dato2 nvarchar(30),
Dato3 nvarchar(30),
Dato4 nvarchar(30),
Valor1 int,
Valor2 int,
Valor3 int,
Valor4 int,
Valor5 int
)
goInsertar 3 millones de registros. Puede probar con menos registros, esta inserción puede llevar algo mas de 20 minutos, dependiendo de la velocidad y memoria de su equipo.
set dateformat dmy
Set nocount on
Declare @Valor int = 1
While @Valor <= 3000000
Begin
Insert into dbo.Prueba
([Codigo], [Fecha], [Dato1], [Dato2], [Dato3], [Dato4],
[Valor1], [Valor2], [Valor3], [Valor4], [Valor5])
values
(
@Valor,
DateAdd(d,@Valor,'01/01/1920'), -- Añadir un día al siguiente registro
'Dato texto ' + Cast(Round(Rand()*100,0) As nvarchar),
'Dato texto ' + Cast(Round(Rand()*100,0) As nvarchar),
'Dato texto ' + Cast(Round(Rand()*100,0) As nvarchar),
'Dato texto ' + Cast(Round(Rand()*100,0) As nvarchar),
Round(Rand()*200000,0), Round(Rand()*200000,0),
Round(Rand()*200000,0), Round(Rand()*200000,0),
Round(Rand()*200000,0)
)
Set @Valor += 1
End
goEl listado de los registros de la tabla prueba
select * from dbo.prueba
go
El resultado se muestra en la siguiente imagen

Creando índices no agrupados
El índice B-Tree no agrupado.
Create nonclustered index PruebaDato1Valor1IDX on Prueba (Dato1, Valor1)
go
El índice ColumnStore no agrupado.
Create nonclustered columnstore index PruebaDato1Valor1ColumnStoreIDX on Prueba (Dato1, Valor1)
go
Gobernador de recursos Resource Governor
El regulador de recursos de SQL Server es una función que puede utilizar para administrar la carga de trabajo de SQL Server y el consumo de recursos del sistema. Resource Governor le permite especificar límites en la cantidad de CPU, E / S físicas y memoria que pueden usar las solicitudes de aplicaciones entrantes.
El Gobernador de recursos en SQL Server (Resource Governor) es una funcionalidad que permite administrar el uso de recursos que tiene la instancia para diferentes aplicaciones y usuarios. El Resource Governor se activa en tiempo real al establecer los límites de memoria y CPU, esta opción ayudar a prevenir que una transacción o proceso consuma todos los recursos del sistema.
Modifica la cantidad de memoria máxima a 75% al grupo de cargas de trabajo por defecto.
Alter workload group [default] with
(request_max_memory_grant_percent = 75)
go
Alter resource governor reconfigure
go
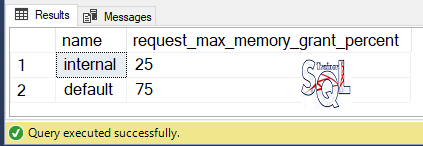
Visualizar los valores de los grupos de cargas de trabajo
Select name, request_max_memory_grant_percent
from sys.dm_resource_governor_workload_groups
go
El resultado se muestra en la siguiente imagen.
Realizando consultas de la tabla Prueba, una de las cuales es usando el columnstore index y la otra con el índice agrupado, ambos con las mismas columnas de indexación.
Consulta que usa el ColumnStore index
Select Dato1, Avg(Cast((Valor1) as float)) As ‘Promedio’
from Prueba
group by Dato1
go
El resultado se muestra en la siguiente imagen.

El Plan de ejecución estimado de la consulta se muestra en la siguiente imagen.


Consulta que usa el indice B-Tree
Select Dato1, Avg(Cast((Valor1) as float)) As ‘Promedio’
from Prueba
group by Dato1
option (table hint(Prueba, index (PruebaDato1Valor1IDX)))
go
El resultado se muestra en la siguiente imagen.

El Plan de ejecución estimado de la consulta se muestra en la siguiente imagen.


IMPORTANTE:
Note la diferencia entre los valores del costo estimado de subárbol.
Valor del costo estimado de subárbol con el Column Store index: 2.5667
Valor del costo estimado de subárbol con el B-Tree index: 15.6488
Obviamente hay una diferencia muy notoria lo que hace muy recomendable usar listado con los índices de tipo Column Store index.
Ejercicio 2
Usando la tabla Order Details de Northwind.
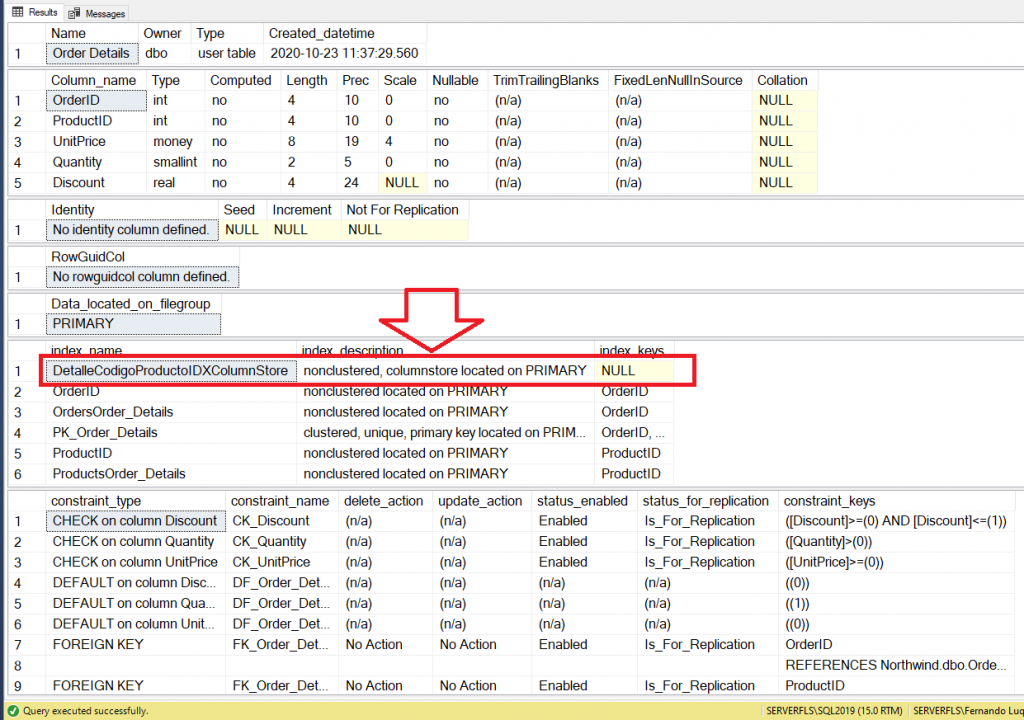
La estructura de la tabla muestra los índices
sp_help [Order Details]
go
El resultado se muestra en la siguiente imagen.
Note que existe el índice para el campo ProductID

Mostrar las unidades vendidas por producto. Se obtendrá el resultado usando un índice B-Tree versus el uso de un ColumnStore index.
select
D.ProductID As ‘Código’,
Sum(D.Quantity) As ‘Cantidad’
from [Order Details] As D
group by D.ProductID
Order by D.ProductID
go
El resultado se muestra en la siguiente imagen.

El resultado del plan de ejecución estimado y el costo estimado de subárbol se muestra en la siguiente imagen.

Crear el columnstore index para el campo ProductId
Create nonclustered columnstore index DetalleCodigoProductoIDXColumnStore
on Order Details
go
En la vista indexes se puede visualizar el índice creado
select * from sys.indexes
where name like ‘Detalle%’
go
Al visualizar nuevamente la estructura de la tabla
sp_help [Order Details]
go
El resultado se muestra en la siguiente imagen.
Note que ahora existe además de todos los índices un ColumnStore Index.
Listar nuevamente los productos y las unidades vendidas.
select
D.ProductID As ‘Código’,
Sum(D.Quantity) As ‘Cantidad’
from [Order Details] As D
group by D.ProductID
Order by D.ProductID
go
El resultado del plan de ejecución estimado y el costo estimado de subárbol se muestra en la siguiente imagen.

Note la diferencia:
Sin el ColumnStore index el costo de subárbol estimado es de: 0.0523268
Con el ColumnStore index el costo de subárbol estimado es de: 0.0192329
Eliminar el column store index.
Drop index DetalleCodigoProductoIDXColumnStore on [Order Details]
go
Convertir un índice B-Tree en ColumnStore index
Ejercicio 3
Crear una tabla, luego crear el índice agrupado B-Tree y luego convertirlo en un ColumnStore index.
CREATE TABLE MiTabla
(
MiTablaCodigo nchar(4) not null,
MiTablaFecha Date,
MiTablaCantidad Numeric(9,2),
MiTablaDescripcion nvarchar(50)
)
go
Crear el índice agrupado
Create CLUSTERED INDEX MiTablaPK ON MiTabla (MiTablaCodigo)
go
Convertirlo a column store index
Note que se especifica el mismo nombre del índice
y se adiciona la palabra ColumnStore. Adicionalmente como el índice existe se incluye la opción DROP_EXISTING = ON.
Create CLUSTERED columnstore INDEX MiTablaPK ON MiTabla
WITH (DROP_EXISTING = ON)
go
Creando un NonClustered columnStore index
Primero convertir el Clustered columnStore index en B-Tree index.
Create CLUSTERED INDEX MiTablaPK ON MiTabla (MiTablaCodigo)
WITH (DROP_EXISTING = ON)
go
Crear el Nonclustered columnStore index
if exists
(select name from sys.indexes
where name = ‘MiTablaIDXColumnStore’)
Begin
Create NonCLUSTERED columnstore INDEX MiTablaIDXColumnStore
ON MiTabla (MiTablaFecha, MiTablaCantidad)
with (Drop_existing = on)
End
Else
Begin
Create NonCLUSTERED columnstore INDEX MiTablaIDXColumnStore
ON MiTabla (MiTablaFecha, MiTablaCantidad)
End
go
Para mostrar la estructura de la tabla MiTabla
sp_help MiTabla
go
